Agentic AI applications are seeing a huge rise in adoption across the enterprise community, signaling a fundamental shift in how businesses will interact with customers in the future.
To truly deliver on this promise, production-grade agentic workflows must excel across four common pillars –
1) Security,
2) Fastness,
3) Accuracy,
4) Reliability.
Achieving this level of performance goes beyond prompt engineering. It requires optimizing the underlying system’s architecture. By fine-tuning key infrastructure parameters, engineering teams can drastically improve these core characteristics.
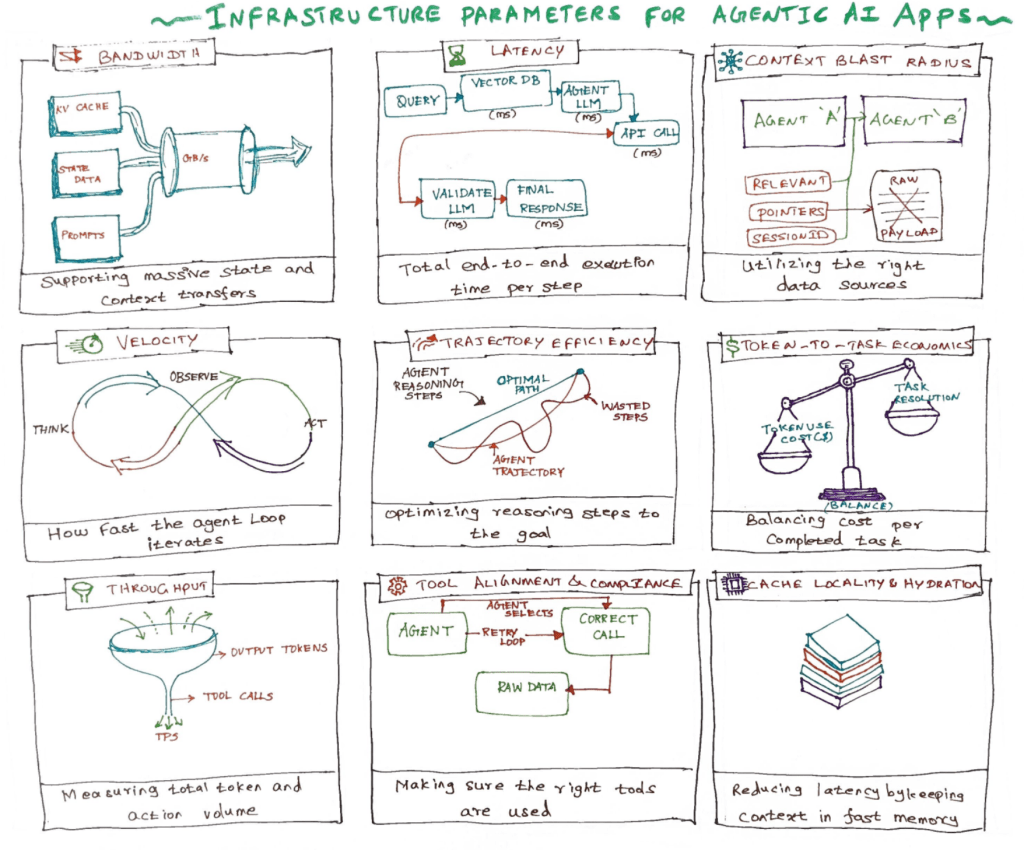
In my experience, I found there are 9 fundamental parameters that can help us to keep the checks and balances clear. Let’s take a look at each of these parameters one by one to see how they reshape the execution stack.
1. Bandwidth –
What is it? Beyond the standard network pipes, bandwidth in Agentic AI refers to the system’s capacity to transfer large volumes of data, such as KV caches, multimodal data streams, and full conversational prompts, between compute instances.
Why does it matter? Agents rely on memory and conversation history to make decisions, and if bandwidth can not accommodate the whole heavy context window, then it slows down the entire agentic system.
How to achieve it? Pass lightweight context references (pointers or session IDs) between agents rather than transferring raw, redundant text payloads.
2. Latency –
What is it? Latency is the total end-to-end execution time required to complete a single, multi-hop agentic loop (from user query, through vector databases, LLM reasoning steps, and external API calls, to the final validation).
Why does it matter? Users expect a highly interactive session that feels like interacting with humans. Quick and valid responses give more confidence to the users as they utilize the system.
How to achieve it? Execute independent agent tasks or tool calls in parallel rather than chaining them entirely sequentially.
3. Context blast radius –
What is it? It measures the optimization and control of data shared between microservices or agents during a handoff, ensuring that only relevant context is passed forward.
Why does it matter? When Agent A tells Agent B everything instead of just what it needs to know, it creates data proliferation. This wastes expensive input tokens, increases processing time, and compromises security by leaking unnecessary state data to external nodes.
How to achieve it? Utilize centralized state managers or caches so agents pull precise data on demand instead of pushing bloated payloads.
4. Velocity –
What is it? Velocity measures the physical iteration rate of the agent’s internal OODA loop (Observe, Orient, Decide, Act). Essentially, how fast the agent can ingest a data stream, update its internal state, and fire off the next command.
Why does it matter? Velocity determines the agility of the agent. It is again important for a solid user experience.
How to achieve it? Stream inputs and outputs asynchronously instead of waiting for full block generation.
5. Trajectory efficiency –
What is it? It is the ratio of actual reasoning steps an agent takes to resolve a user goal versus the absolute most direct, optimal path.
Why does it matter? An agent might process text quickly, but if it falls into an algorithmic loop or takes 15 confused steps to solve a problem that required only 3, it is highly inefficient. Maximizing trajectory efficiency directly drives accuracy and reliability. In my view, this is a way to analyze and reduce the spending on agents.
How to achieve it? A combination of self-correcting steps to catch the mistakes early and fine-tuned routers will help improve efficiency.
6. Token-to-task economics –
What is it? The total number of tokens it took to finish a task.
Why does it matter? Speed and accuracy mean nothing to an enterprise if answering a single customer service query costs $2.00 in API compute. Maximizing this parameter ensures the application achieves a positive ROI at scale.
How to achieve it? Route simpler tasks to smaller, open-source local models (like Llama or Mistral) and reserve expensive frontier models strictly for complex reasoning. Implement aggressive prompt caching to avoid paying for static system prompts repeatedly.
7. Throughput –
What is it? Throughput is the measure of the total volume of data an agentic system processes over time in 2 areas – 1) Tokens per second (TPS) generated, and 2) Tool/API calls successfully managed.
Why does it matter? Without strong throughput, the application will drop requests or crash when hundreds of autonomous agents trigger recursive backend tasks at the same time.
How to achieve it? Efficient semantic caching and preloading of data can reduce the number of calls to agents and serve the user’s needs right from the API gateway layer itself.
8. Tool alignment & compliance –
What is it? This parameter evaluates how accurately and reliably an agent selects the correct external tool and formats its arguments to strictly match the destination schema on the first try.
Why does it matter? The right invocation of tools increases reliability and prevents wasted compute cycles.
How to achieve it? Provide clear, concise, and distinct tool descriptions in the system prompt so the model easily differentiates between available actions.
9. Cache locality & hydration –
What is it? Cache Locality is the process of keeping an agent’s persistent system instructions, tools, and dynamic KV cache hot and ready within the fastest available memory layer (like GPU HBM) close to the model execution node.
Why does it matter? When an agent loops repeatedly, fetching its core context from slow system memory every time introduces severe latency bottlenecks. Keeping the memory hydrated ensures instantaneous responses on consecutive loop steps.
How to achieve it? Find the best memory solution that your cloud provider offers for better performance.
Building the agentic AI app is no longer just a dataset challenge, or an infrastructure pipeline challenge, or writing a clear prompt. It is also an optimization challenge cutting across the entire distributed systems. As we move the prototype to production-grade deployments, balancing the raw infrastructure power, like bandwidth and latency, by utilizing algorithmic parameters like trajectory efficiency and tool compliance, becomes necessary.
By systematically tuning these nine parameters, we ensure our agents don’t just execute, but do so with the exact security, speed, accuracy, and reliability our enterprise demands.
The future of customer interaction belongs to the autonomous agent.
The future of the agent belongs to the architecture supporting it.
Share your learning on how you are efficiently building the agentic AI apps.
Happy learning!
