As businesses grow bigger, there is a huge amount of data that is being collected by the different systems. With the emergence of GDPR, CCPA, and many other privacy regulations, there are lots of changes in the way the data is collected. The data are collected anonymously without being tagged to an individual. Businesses collect the data to understand, recommend and personalize the customer experience. So the data collected should be used in some way or the other. However, the data will be in a raw format with different schemas and so on. First, the data has to be made available in a way that the business can utilize it for some purpose.
What is ETL? – Extract, Transform and Load is not new terminology in computer science. It has been there since the inception of big data. There has been quite a lot of tools and vendors in the market to help with –
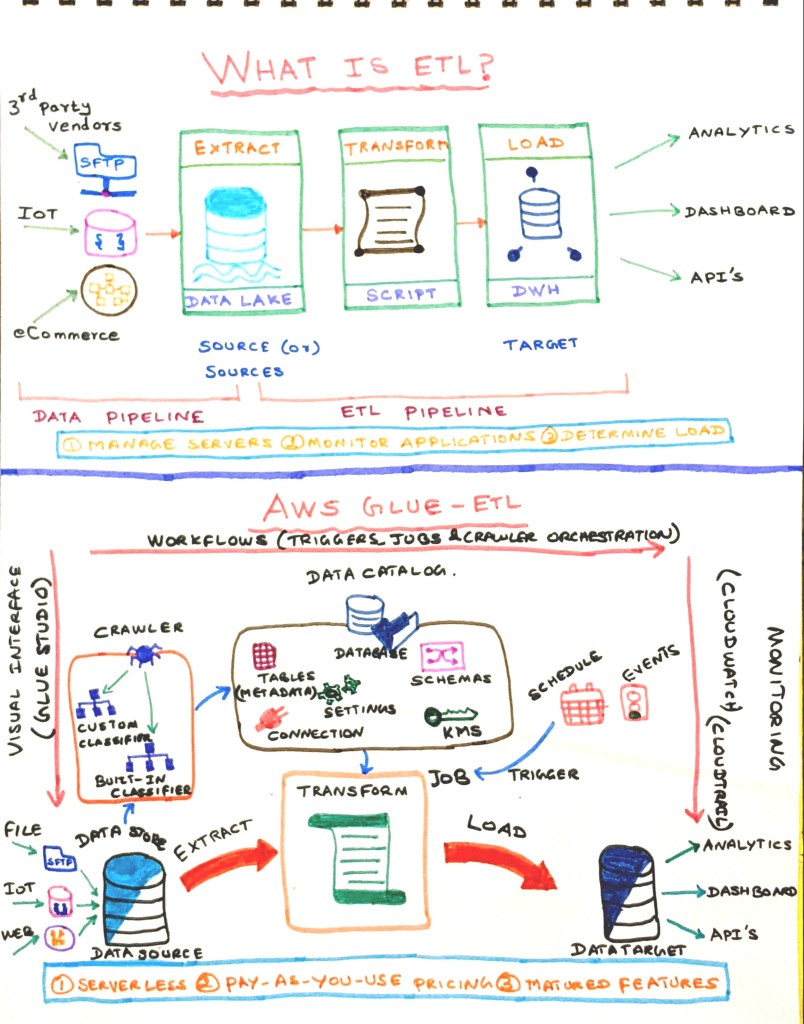
- Setting the data pipeline to move the data from a source to target (This target would be a source for ETL pipeline)
- Setting up the ETL pipeline and move the data to DWH systems
- Utilize the data from DWH to present business intelligence, dashboards, API’s and so on
What are some of the challenges faced in ETL? – Businesses want to stay closer to the customer and provide a unique customer experience in a faster way beating their competitors. Big data and analytics help businesses in understanding a customer and provide them more digital engagement using their unique offerings. As the data size grew to PB scale, it needs more hands to handle the ETL jobs. This means more trained ETL developers, DWH specialists, and so on. Also, a lot of custom code needs to be written for the ever-changing data. Meanwhile, the cloud on the other hand was moving from IaaS to serverless software solution offerings addressing specific problems. These SaaS solutions provide the business to scale faster, easy-to-use ETL workflows, spend less time on managing servers, less time on monitoring the applications, less time on determining the workloads, taking care of security and governance, etc.
What are the options with the major cloud vendors? – All the 3 major cloud vendors provide 1) Serverless options for ETL, 2) No to low code development, 3) Data clean up and transformation, 4) Pay-as-you-use pricing, 5) More than 99.9 percent SLA, 6) Most common governance, compliance and security features, 7) Very little learning curve, 8) Integration with data lakes within their ecosystem, 9) Connection to DWH systems, 10) Integration to 3rd party vendors using connectors.
1. Azure Data Factory (ADF) –
Azure Data Factory is Azure’s cloud ETL service for scale-out serverless data integration and data transformation. It offers a code-free UI for intuitive authoring and single-pane-of-glass monitoring and management. You can also lift and shift existing SSIS packages to Azure and run them with full compatibility in ADF. SSIS Integration Runtime offers a fully managed service, so you don’t have to worry about infrastructure management.
https://docs.microsoft.com/en-us/azure/data-factory/
2. AWS Glue –
AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, machine learning, and application development. AWS Glue provides all of the capabilities needed for data integration so that you can start analyzing your data and putting it to use in minutes instead of months.
https://aws.amazon.com/glue/
3. Google Cloud Dataflow –
Dataflow is a fully managed streaming analytics service that minimizes latency, processing time, and cost through autoscaling and batch processing.
https://cloud.google.com/dataflow
Let us see AWS Glue in detail –
AWS Glue is a convenient tool to use for simple to complex ETL pipelines and transformation. There are 3 main components involved in Glue. Let us see one after the other.
1) Data Catalog – Data catalog holds the needed information to perform the ETL transformation. Data catalog has the following components –
| Si No | Components | Explanation |
| 1 | Databases | Collection of table definitions organized in a logical group. Each database can have multiple table definition within it |
| 2 | Tables | Metadata information including the schemas will be stored in tables. A table does not hold any data, it just holds the metadata of the data set. A table can be added in 3 different ways – 1) Using crawler, 2) Entering manually, and 3) Using the existing schema |
| 3 | Connections | ETL has 2 different data stores – 1) Data source, and 2) Data target Connections hold the properties to connect to the data |
| 4 | Crawlers | Crawlers are the most important component. They connect to the data source, scan the data set based on the classifier definition to determine the schema of the data. Crawlers write these schemas to the tables as metadata |
| 5 | Classifiers | They are used by the crawlers while scanning through the source data to determine the schema. Classifiers can be of 2 types – 1) Built-in classifier, and 2) Custom classifier |
| 6 | Schema registries | It is a logical grouping of schemas. There can be up to 10 registries per AWS account per AWS region. Schema registry acts as a central place to discover, control and manage the schemas |
| 7 | Schemas | A schema defines the structure and format of a data record. A schema is a versioned specification for reliable data publication, consumption, or storage. It supports Apache Avro as the only data format option for now. There are 5 different compatibility modes in schemas – 1) Backward (Default) 2) Backward all 3) Forward 4) Forward all 5) All There can be up to 1000 schema versions per AWS account per AWS region. Also, a maximum of 10 key-value pairs per SchemaVersion per AWS region. |
| 8 | Settings | Provides a way to add encryption and permissions for the data catalog. 1) Encryption – A) Metadata encryption and B) Encrypt connection passwords 2) Permissions – Fine-grained access control of the data catalog |
2) ETL – This holds the needed information to create the ETL Job. ETL has the following components –
| Si No | Components | Explanation |
| 1 | AWS Glue studio | A visual interface for 1) Creating the job, and 2) monitoring the job runs |
| 2 | Workflows | It is an orchestration used to visualize and manage the relationship and execution of multiple triggers, jobs, and crawlers. Max concurrency lets the developer define the maximum number of concurrent runs that are allowed for the workflow |
| 3 | Jobs | This is the core component of Glue. We describe how an ETL process from the data source should migrate to data target using Jobs. There are 5 main steps in defining the job 1) Job properties – A) Specify the type (Spark, Spark streaming, and Python shell) and mention how the job should run (Automated script vs existing script vs a newly authored script) B) Job bookmark – Specifies how AWS Glue processes job bookmark when the job runs. It can remember previously processed data (Enable), update state information (Pause), or ignore state information (Disable) C) Enable the needed monitoring options D) Specify the Security configuration, script libraries, and job parameters as per the requirement 2) Data source – Define the data source by choosing the database and location 3) Transform type – Change schema or find the matching record 4) Data target – Choose the data target by selecting the connection 5) Schema – Perform the schema mapping between the source and the target datasets |
| 4 | ML Transforms | Helps to clean the job using ML transforms |
| 5 | Triggers | Triggers are used to initiate the Job. There are 3 types of triggers – 1) Schedule, 2) Job events, and 3) On-demand |
| 6 | Dev endpoints | It is an environment used to develop and test the Glue scripts |
| 7 | Notebooks | A notebook enables interactive development and testing of your ETL scripts on a development endpoint |
3) Security – Different set of properties to encrypt the data-at-rest.
| Si No | Components | Explanation |
| 1 | S3 | Enable at-rest encryption when writing data to Amazon S3. There are 2 ways to encrypt – 1) SSE – KMS, and 2) SSE – S3 |
| 2 | CloudWatch | Enable at-rest encryption when writing logs to Amazon CloudWatch. This uses the key from KMS |
| 3 | Job bookmark | Enable at-rest encryption of job bookmarks. This uses the key from KMS |
As easy as it is to use Glue and in a majority of cases Glue can be used as an ETL tool, there are some limitations, concerns, and known issues in using the product. Go through the detailed documentation before choosing to go with Glue.
Moving to the cloud and starting to utilize cloud offerings provide a competitive edge for businesses. This is just the beginning of the new era in development strategies and methodologies.
Share your thoughts in the comments!
Happy learning!
