Rapid Application Development(RAD), over the years, have been been a key element for the successful application development process. This uses rapid prototyping and iterative delivery, which is a sharp contrast to the typical waterfall development methodologies. In other words, ‘fail fast – learn fast’ is the new-gen development process.
Typically there are 2 main categories when it comes to application development. One is the frontend and the other is the backend.
What is a frontend? And how fast are development life cycles here? – Most commonly, Frontend development involves a visual/speech/gesture/mixed-reality way of showing the needed data to the users for any of the user intended CRUD operations. In recent years, many frameworks have emerged for areas not limited to cross-platform development, responsive UI, ubiquitous computing, mixed reality, etc. Depending on the development needs the right platform can be chosen and applications can be developed rapidly.
What is a backend? And how fast are development life cycles here? – Backend development is an enabler for frontend. Backend is typically responsible and performs the CRUD operations requested by the frontend. This is always the most critical part. Earlier, it was not just the code, but the developers are responsible for deploying the code in the infrastructure and making it highly available and scalable as the demand or the load increases. During the initial stages of cloud computing, the majority of the vendors provided only IaaS. Currently, cloud computing is a decade old and offers a majority of the functionalities and products as managed services which are nothing but ‘Serverless computing’
Serverless computing has reduced the efforts or the time needed by the developers or the DevOps team in managing the infrastructure. Not only this but it also has changed the paradigm of programming for good. Developers can focus on solving the actual business problem rather than worrying about the infrastructure. Now let us see in detail the serverless computing blocks needed to develop a full-fledged application.
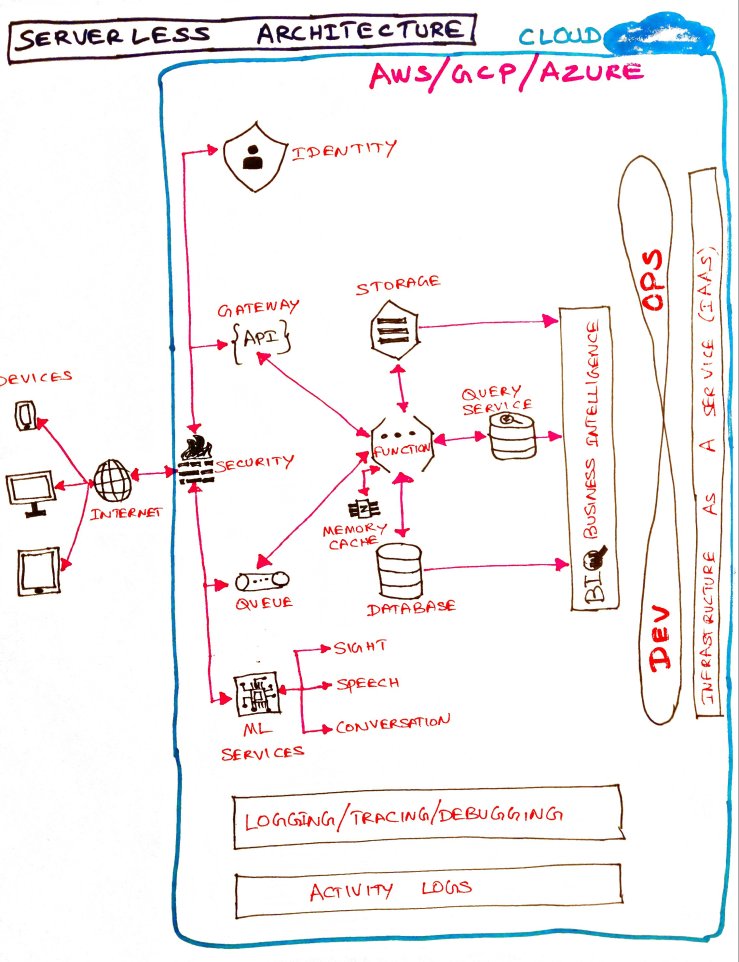
1) Identity – Identity as a Service (IDaaS) is provided by cloud providers. Identity is provided either through their solution or through federated identity. They also provide OAuth standard tokens and claims which provide authentication (authN) and authorization (authZ) functionality out of the box.
2) Security – Web application firewall helps in filtering the HTTP request based on the access control list’s (ACL) rules and conditions. Managed Distributed Denial of Service (DDoS) provides safety for the application running on the cloud. Both combined helps in the protection of data, application, and infrastructure in cloud computing.
3) Gateway – API gateways act as a single point of entry for the frontends to communicate with the backend in the form of REST or GraphQL. Gateways can be customized for a specific vendor and be accessed by a vendor based on the API key. In addition to this, the usage limit can also be set for a specific vendor to protect the service from being over-utilized.
4) Functions – These are core elements in serverless computing where the actual code (Business logic) runs. Functions can be exposed through API gateways for frontends to consume as a service or can be used as an action for triggers in case of event-driven architecture. Cloud providers provide varieties of runtimes like Node JS, Python, Go, Java and some vendors even provide you the option to bring your own runtime.
5) Memory Cache – Memory store or cache is crucial for the low latency transactions and to reduce the number of database transactions to read the same data again and again. Redis in-memory data store is the industry standard and an open-source. All of the cloud providers also provide ways to migrate the on-prem existing Redis cache to their respective managed Redis cache service.
6) Storage – When the Enterprise first tries to move its service to the cloud, the first thing they may try is the cloud storage options. These managed services are fairly simple and easy to use. They come with different classes of storage depending on the needs and the long term storage. Static hosting can also be done through cloud storage.
7) Database – When your business is running globally, running and managing a global-scale database gets more complex. Cloud providers provide globally distributed scalable and strongly consistent database engines. In some cases, applying patches to the software and taking the backup of the data can be done automatically in a specified time window.
8) Query engine – This is commonly needed to analyze the data in rest using interactive query services. Petabyte scale storage and transactions with millions of requests per hour are easily handled through managed database services from cloud providers. Managed database service is provided for both SQL and NoSQL databases.
9) ML services – Machine Learning as a Service (MLaaS) on a variety of use cases like image recognition, video intelligence, natural language processing, the language translation is provided on the go by all of the cloud service providers.
10) Pub/Sub queues – A fully cloud-managed real-time messaging service. Common uses cases include collecting the event analytics, processing the order, etc. Cloud providers provide a variety of functionalities in the queue to set the number of days the message can live in the queue to move the message to a Dead Letter Queue (DLQ) in case of unsuccessful processing of the messages in the queue. This is a very powerful managed services component which can handle many use case and also takes very little time for developers to understand and implement.
11) Business Intelligence – Data will be collected and stored in different channels. Business needs different dashboard and reports to make smarter business decisions. BI tools provided by the cloud providers come in handy for this purpose. Also, they provide the connectors needed to connect to a variety of data channels with just one click.
12) Logging, tracing and debugging – There should be a way to collect monitoring, operational and application logs that are running in the cloud. Tracing helps in collecting the latency data from the different applications hosted and running on the cloud. The debugger lets to inspect the state of the running code in any environment in real-time. All these tools combined provide a good developer tools to run and manage the application on the cloud.
13) Account activity logs – There should be a way to know the identities who have created, modified or deleted a cloud resource. This is needed for enabling governance, compliance, and auditing of your cloud account. By default, this service is enabled in the account and can be accessed by identities when the specific roles are attached to their identity.
14) DevOps – Starting from writing the code needed for cloud functions to packaging it to deploying the same, cloud providers provide tools for the same. There are no trained DevOps engineers needed to perform all of these operations. With serverless computing, the developers can handle this as well since this is a one-time setup and very little time is needed to deploy and in cases, even the deployment can be automated based on conditions.
15) Infrastructure as a Service (IaaS) – Atlast, once when the serverless architecture is finalized for your solution, it is not a recommended practice to configure the infrastructure needed for serverless computing through console or CLI. We have to make sure that we create the infrastructure needed in the form of a configuration file. With this, we can easily roll out development, testing, and prod environments in minutes and with the confidentiality that all of the environments are configured the same way with no manual errors.
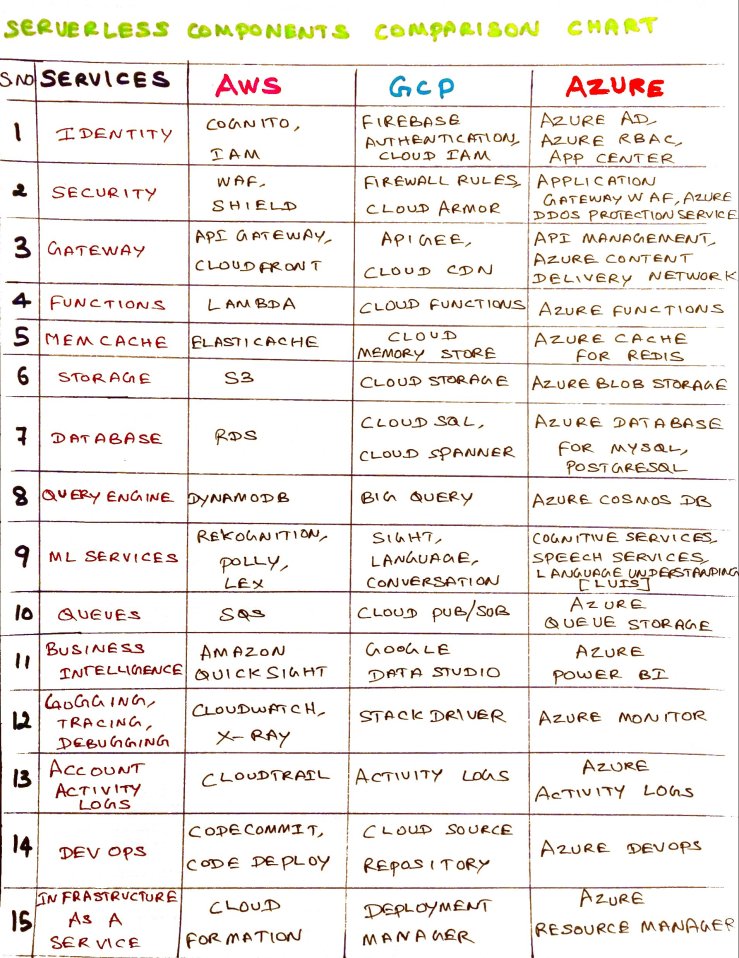
Serverless components comparison chart – AWS vs GCP vs Azure:
As you can see, it is fairly simple to design a full-fledged application using serverless backend architecture. There is no need to worry about designing a highly available resilient architecture. Also, when you are unsure about the load, it is wise to choose pay as you go model (with serverless computing) rather than going with a long-term IaaS commitment.
However, this doesn’t mean that everything can be done in a serverless computing fashion. There are pros and cons to serverless computing. Some of the cons being 1) Cold start with serverless functions, 2) Debugging of code, 3) Cloud-agnostic architecture, 4) Increasing cost with usage, and most importantly 5) the mindset with developing in a serverless computing model. Even though, in its early days, serverless computing is trying to bridge the gap with the traditional server-backend architecture.
Please share your experience and comments on building a serverless architecture.
Happy learning!
