Emergence of Artificial Intelligence means processing of huge data sets. These data sets has to be stored in some disks or some persistence storage. The huge volume of data has to be processed by the data scientist or big data analyst to come up with an algorithm or model that yields a measurable outcome.
What are the challenges in storing huge volume of data?
1) The first and foremost challenge is security
2) Bandwidth to take the data to and from cloud systems
3) Complexity in managing unstructured data
4) SMART IDENTIFICATION OF REDUNDANT DATA –
A self driving car can generate details about fuel consumption or remaining fuel or speed or time to reach destination, etc, very often. Many studies say that a self driving car can generate 20 to 30 GB of data every 1 hour very easily. Similar will be the case with any smart systems. Any system to be smart will generate data and the same data later will be used by ML tools to make the device learn on its own.
The recent unfortunate accidents with Tesla and Uber made me think on the data processing capacity of the smart machines. If the speed of processing of data have been faster could that accident be averted? If the right data was processed at the right time could the accident be averted? These are just some thoughts out of curiosity. In fact, curiosity is the mother of next advancement.
I think smart systems to be smarter needs the right data to be processed. More data doesn’t mean more exact outcome. Only the right data can give you more accurate predictions. One simple solution might be to avoid redundant data and the challenges surrounding it.
How can we smart reduce the redundant data?
Lets first understand the core fundamentals of Big data – 3 V’s
Even though there are different types of V’s, let’s take into scope the very fundamental or basic V’s.
Volume – The most important V which refers to the huge amount of data
Velocity – Refers to how often and how fast data is generated and sent to systems
Variety – Number of types of data or different types of data representing some characteristics
For the big data analyst to derive predictions and analyze possible outcomes the core fundamentals on big data should not be compromised in the name of reducing redundant data.
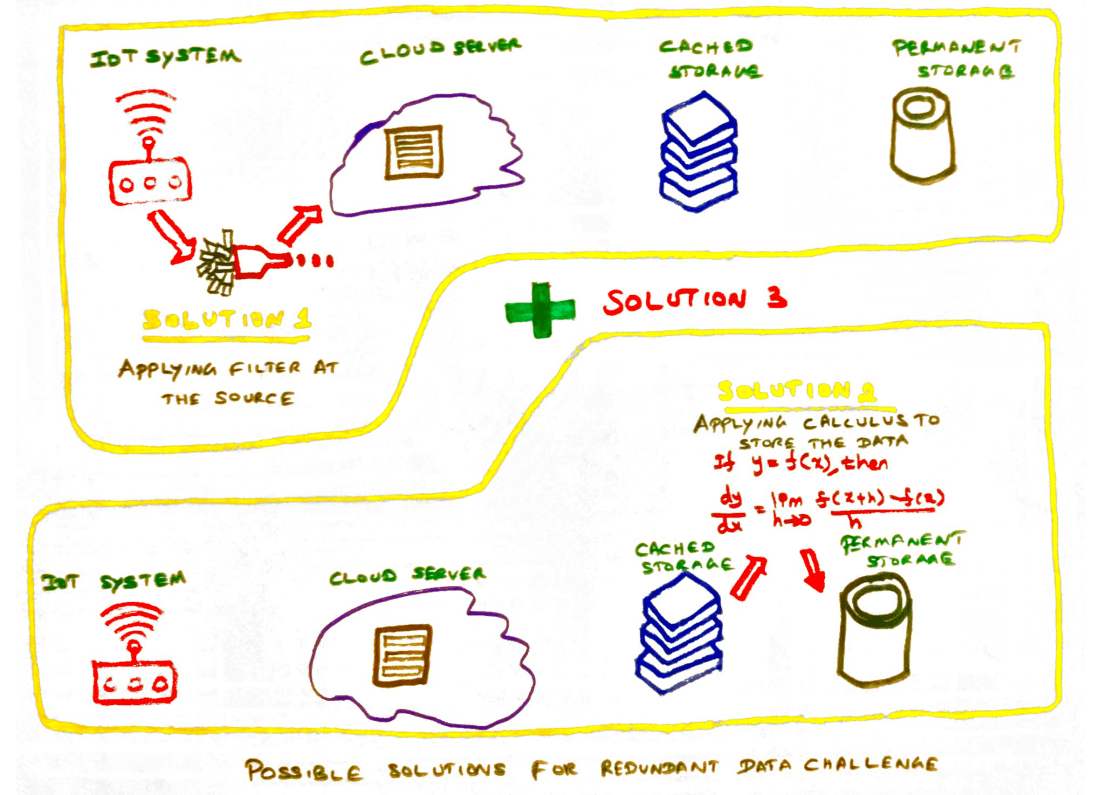
Possible solutions for redundant data challenge
Solution 1 – Applying Filters at data collection source
One simple solution can be adding the right filter on the devices which generate large data. A simple analytical solution installed with the device can reduce the redundant data inflow to the system while retaining the core fundamentals of big data.
Solution 2 – Applying calculus while storing the data
Differential calculus is just one piece in mathematics which helps in deriving the rate of change. If a rate of change on the data can be expressed in a simple formula using differential calculus then a huge set of data can be stored as one line item. And at the same time the same data can be replicated from the simple/complex formula that was stored.
Solution 3 – Combining solutions 1 and 2
Reduction in data at the source with right filters and storage of data by applying differential calculus will reduce many of the challenges that we discussed above like –
i) Less bandwidth utilization
ii) Less storage space
iii) More meaningful data
Many challenges are solved by finding solutions to the problem in other plane rather than the current plane.
Please post interesting challenge that you are trying to resolve.
Happy learning!

Interesting Article 🙂 . These indeed are innovative solutions to minimize the bandwidth and storage required for handling Big Data. However they might need some refinement before we see their final working versions.
The device generating big data are normally sensors or mobile devices so they might not have sufficient storage space to store historical data for comparing and removing redundant data. The best we might do is to remove redundant data for last 1 hr or so.
Storing a formula instead of data is an interesting approach. I am thinking about this in terms of storing a mathematical model instead of data. This could be a linear regression model or a random forest model etc. The problem i see with this is that we lose the outliers in the data and the data quality would be as good as the model. For eg. If the accuracy of the model is 80% i.e. the model predicts accurately only 80 % of the times, then the data we get from the model in future would also be only 80% accurate. 20% of the observations/data reported by the model would be false.
I agree that for bringing the next big revolution in Big Data arena we need to think in other plane 😀
LikeLike
Thanks for sharing your thoughts around it. I agree that it would mostly look like a linear regression model in case if we start storing data as formulas. I think this has to be considered case by case depending on the use case.
LikeLike