The rapid adoption of Generative AI has forced organizations into a ‘safety-first’ approach. For most, the starting line was guardrails. These include wrapper-based filters, prompt shields, system instructions, and more. They are designed to keep models from going off the rails.
AI agents have moved beyond simple chatbots. They have become autonomous systems that can execute code, access databases, and interact with web tools. Therefore, static guardrails are no longer enough. We are entering the era of Zero-Trust AI Architecture. The philosophy shifts from ‘Keep the AI safe’ to ‘Assume the AI (or its input) is already compromised’.
The limit of guardrails – Why they are not enough?
Guardrails are essentially a ‘best-effort’ perimeter. They focus on the content of the conversation—filtering out PII, toxic language, or jailbreak attempts. However, they suffer from three major flaws in my view –
- They are reactive – Attackers are constantly finding new ways to ‘bypass’ the system prompt (Example – Many-shot jailbreaking).
- They lack context – A guardrail might block a ‘delete’ command in a prompt, but it doesn’t know if the AI actually has the authorization to delete that specific file in the backend.
- They treat AI as a monolith – Guardrails often assume the threat comes from the user. In reality, the threat can come from indirect prompt injection (malicious data the AI reads from the web) or compromised third-party plugins.
The shift to zero-trust AI
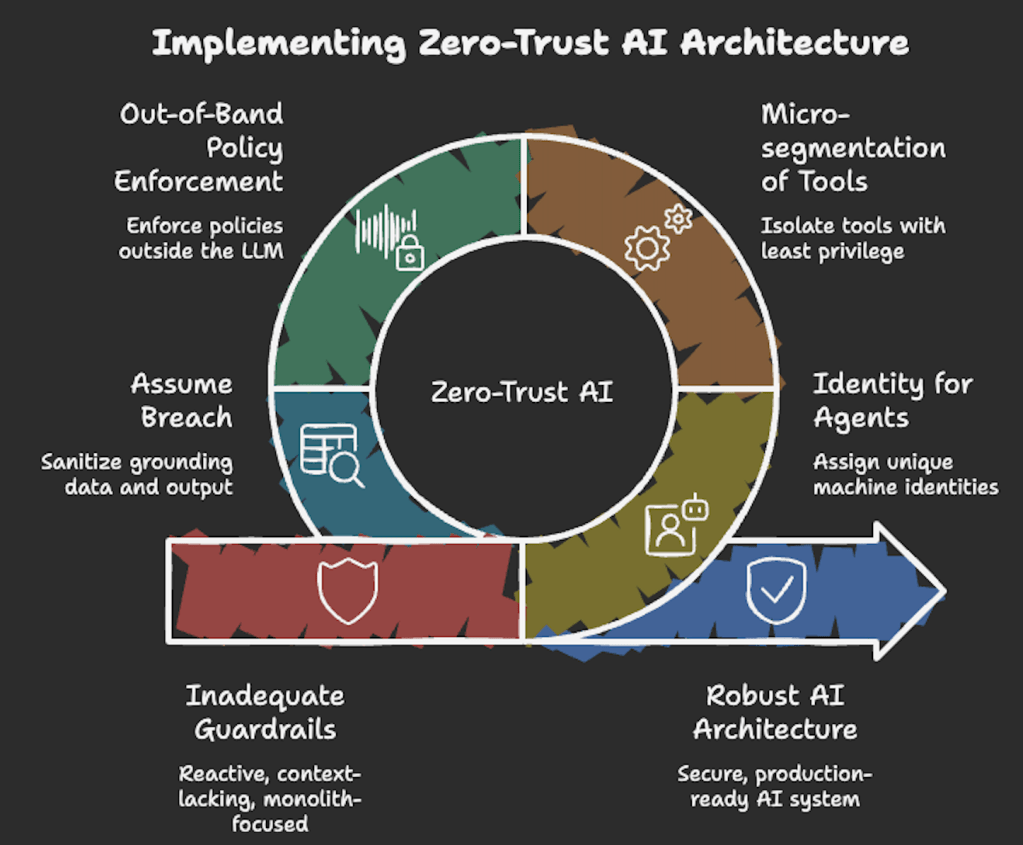
A Zero-Trust AI architecture applies the core principle of ‘Never Trust, Always Verify’ to every component of the AI stack. This includes the user, the model, the data, and the tools.
1. Identity for AI agents
In a zero-trust model, an AI agent isn’t just a script, it’s a first-class identity. Just as you give an employee an account with specific permissions, an agent should have its own machine identity. This applies even to a specific session. Example – An Entra ID or a unique service principal. This allows for precise auditing like ‘Who authorized this action, and which agent executed it?’
2. Micro-segmentation of AI tools
If your agent uses the Model Context Protocol (MCP) or plugins, each tool should be isolated.
- The principle of least privilege – An agent meant to summarize emails should only have read access to the email API. It should not have delete access. It certainly shouldn’t have access to the database.
- Ephemeral credentials – Do not use hardcoded API keys. Use short-lived, just-in-time tokens instead. These tokens expire as soon as the specific task is complete.
3. Out-of-band policy enforcement
This is the biggest shift. Security policies must be enforced outside the LLM. Relying on the AI to obey a system prompt is unreliable because it can be ignored if the model is jailbroken.
- The gateway pattern – An AI gateway sits between the model and the internet/internal data. It inspects inputs and outputs, enforces rate limits, and validates that the agent’s requests align with corporate policy before they ever reach the model.
- Hard-coded validation – If an agent suggests a $10,000 refund, the ‘Send’ button shouldn’t be controlled by the AI. A separate, non-AI logic layer must verify the user’s balance and the agent’s authority before the transaction executes.
4. Assume breach (The ‘content sanitization’ rule)
In Zero Trust, you assume the model’s output could be malicious.
- Sanitize grounding data – Before feeding a PDF or a website’s content into your AI’s context window, run it through a ‘Prompt Shield’ to strip out hidden data and instrucitons.
- Clean the output – Treat AI-generated code or data as ‘untrusted’. For example, if the AI generates a Python script, execute it only in a disposable, sandboxed environment with no network access.
| Feature | Legacy guardrails | Zero-Trust AI |
| Primary Goal | Prevent bad outputs | Limit blast radius of a breach |
| Trust Model | Implicit trust after login | Never trust. Verify every API call |
| Control Layer | Inside the prompt (Soft) | Outside the model (Hard) |
| Identity | User-centric | Agent-specific identities |
| Scope | Conversation-focused | Infrastructure-focused |
Security as a design habit
Moving to Zero Trust doesn’t mean deleting your guardrails. It means acknowledging they are your first line of defense. They are not your only one. Give agents unique identities. Enforce least-privilege access to tools. Assume that every piece of data (input or output) is a potential threat. These actions turn an AI prototype into a production-ready system.
The future of AI isn’t just about how smart the model is. It’s about how robust the architecture around it remains when things go wrong.
Share your experience and knowledge in building the zero-trust AI architecture.
Happy Learning!
