Have you experienced the broken context between two separate chats in ChatGPT or Gemini? The answer would be a ‘Yes’ for most of us. This is the memory limitation problem that exists today with many current LLM providers. Popular GenAI chat interfaces like ChatGPT and Gemini provide access to their LLMs, which process inferences from users. However, the LLMs themselves are fundamentally stateless. This means the context between separate chat sessions is neither connected nor stored persistently. The LLM is a standalone entity and does not inherently store any information about individual user attributes or other needed facts. The memory held within the current scope of the context window is ephemeral and is not shared between individual user chats.
In the early stages of implementing chats using LLMs, I used to believe that simply expanding the context window would solve the context awareness issue. I thought tokens could contain all the necessary information. But eventually, it became computationally complex to manage the state of the entire context and also frequently led to the common ‘Needle in a Haystack’ situation. As more and more tokens were added, I realized that the LLM was often missing the crucial little information it should have used to produce the output.
As I worked more to solve the context awareness challenge, it became clear that it is not solely a context window challenge, but rather a solution design challenge. Relying solely on increasing the context window still presents significant challenges:
1) Lack of cost effectiveness: Each token costs money, and maintaining context as tokens within the context window is like maintaining memory in transit rather than at rest. This means we redundantly pay for the same data again and again. Furthermore, the data becomes very unstructured and may not be reusable outside the scope of that single chat.
2) Dilution of contextual relationship: The unstructured context often does not carry any explicit contextual weight on the key information. The large context effectively becomes a set of large instructions rather than truly providing focused context.
3) Lack of cross-platform support: In a multi-LLM chat interface, the content of the context window is inherently tied to the inference of that specific LLM. This close association means the context within the window cannot be fully reused against another LLM. In other words, the memory contained within the LLM’s context window is not LLM-agnostic.
4) Performance degradation: Increasing the context window also increases the time the LLM takes to respond. This will result in a poor user experience once the solution is launched in production, as users will not want to wait for slow responses.
5) Scaling limitations: Eventually, we will hit a dead end on the context window size as more and more context attributes are required to be added to the same window.
6) Overall: Utilizing only the context window to solve the memory problem is a short-term solution that may solve the immediate issue but raises significant concerns about performance and scalability in the future.

So, how do we externalize the memory that can hold the context? In the overall solution, the long-term memory for the context itself must reside outside the temporary context window. User data, external documents, chat history, and so on could be stored in a vector database for efficient semantic search. Whenever the user submits a query, there is a two-step process:
Step 1: Retrieve the Context – The external memory is queried using the user’s input, and the most relevant information is retrieved. This retrieved information is the “needle” that would have otherwise been lost in the long context window (the “haystack”).
Step 2: Augment and Query the LLM – The user query plus the retrieved information are combined and sent into the LLM’s active context window. This augmented prompt is then used by the LLM to produce the context-aware output.
What type of memory is useful for context awareness?
The memory used should not only support storage and semantic search. Hence a simple vector DB search or document search may not be sufficient. The storage should also have the following properties –
Persistent – It must survive the end of a chat session.
Semantic – It must be searchable based on meaning, not just keywords (hence the use of vector embeddings).
Structured/Relational – It should capture relationships such as who said what, when, and in what context. This process often involves building a knowledge graph on top of the vector data.
Human-like – It needs to feature intelligent management. This includes decay, which is smart forgetting of trivial, old data. It also includes recency bias, which prioritizes recent, relevant memories.
Enter Supermemory.ai – The contextual super memory layer
It is a platform that aims to provide universal, intelligent memory layer—a “Memory Engine”—that is LLM-agnostic and user-controlled. Its core mission is to solve the memory limitation problem by bridging the context gap across different AI assistants.
How does super memory store the information?
Supermemory doesn’t just store raw data. It processes it to create an intelligent, searchable knowledge base. The raw data itself is called the document. The document is split into smallest chunk of information called memories. And the memories are related to each other. Everything is associated to the user id for later retrieval based on the user.
Step 1 – Ingestion & Embedding: Data from various sources (text, links, files, documents) is ingested, chunked, and converted into vector embeddings, which capture the semantic meaning.
Step 2 – Indexing & Graphing: These embeddings are stored in a specialized vector and graph database. The graph component is key, as it maps relationships and entities (users, documents, memories) to build a sophisticated understanding that is more robust than a simple vector search.
Step 3 – Intelligent Management: Supermemory applies brain-inspired principles:
- Context Rewriting: Summaries and connections are continuously updated as new information arrives.
- Smart Forgetting/Decay: Trivial or old information fades over time to keep the memory base focused.
- Recency/Relevance Bias: Recently accessed information is automatically given higher priority in retrieval.
What are the different ways that are used to consume supermemory.ai?
1) Memory API/SDK:For maximum control, developers can use the API (or SDKs for Python/Node) to directly manage memories: add, search, update, and delete. This is ideal for building custom memory logic and integrating with specific data sources.
2) Memory Router (Drop-in Proxy): This is the simplest integration. You simply prepend the Supermemory endpoint to your existing LLM provider’s base URL. The Router acts as a smart proxy that automatically intercepts the API call, handles the context retrieval (RAG) and injection, and forwards the augmented prompt to the final LLM.
Quick sample implementation of Supermemory.ai – Seamless LLM Agnosticism –
The objective of this quick implementation is to leverage Supermemory. It manages the conversation context independent of the underlying LLM provider. This allows the user interface to instantly switch between different backends, such as OpenAI, Anthropic, or Groq. It ensures the conversation history and context remain seamlessly continuous.
Full code repo – https://github.com/shankar2686/super-chat-ai


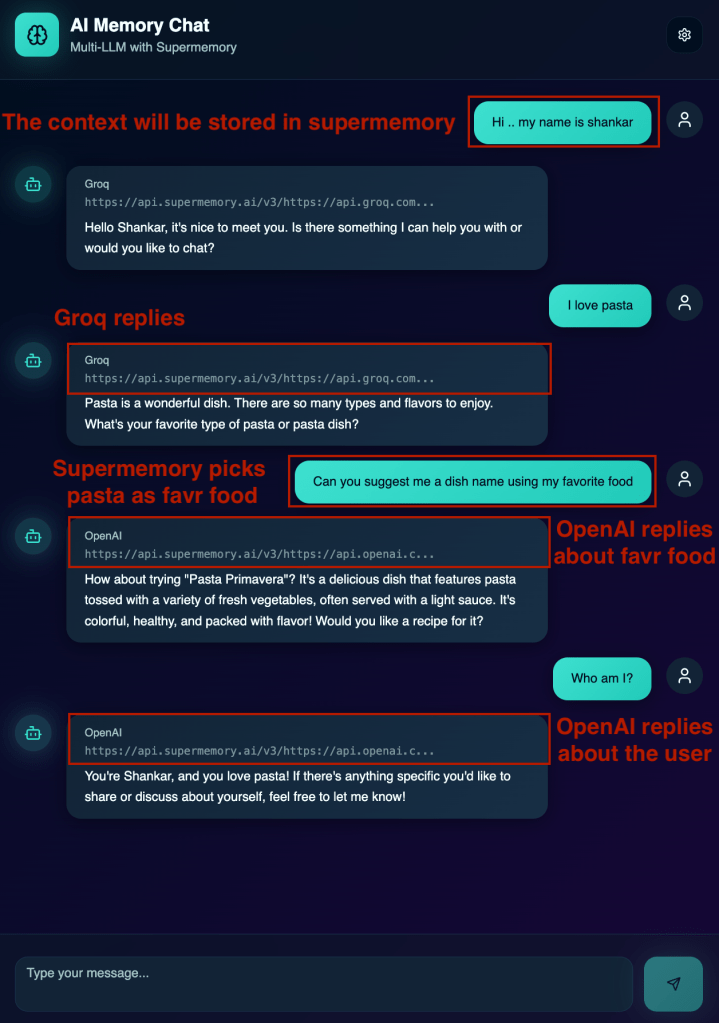
The era of the “stateless LLM” is fading slowly. By externalizing memory into an intelligent, persistent, and portable layer like Supermemory.ai, we move beyond the context window limitation and solve the “broken chat” problem for good.
Share your learning on the tools and platforms that you use to solve the context problem in your own applications!
Happy learning!
