LLMs are mature enough to provide convincing answers to queries, enabling a leap to the next level: a meaningfully useful way to help humans in their day-to-day life. I see AI has a huge potential in offering physical help to humans who are in need. Apart from the regular digital interactions that are offered today as a chat interface, the future would unfold more towards supporting humans using robots, fully autonomous vehicles, unmanned missions to other planets for exploration, coordinated smart sensors that simulate a digital world for more safety, and so on.
So, how will AI expand to the next level?
One of the areas that will be utilizing AI to the next level would be ‘Physical AI’.
What is Physical AI?
It is a new emerging area in AI. This development enables the Digital AI to interpret, interact, and respond to real-world scenarios. Some of the entities that would respond in the real world in the near future are the autonomous machines that we know today as the robots, Autonomous vehicles, smart sensors, etc. Physical AI deals with the real-world environments, including physics and other spatial interactions, much like what humans do. Physical AI would transform autonomous machines into a truly physical AI entity that can listen, interact, respond, and act autonomously with minimal human supervision, with a total understanding of the physical space they are surrounded by.
Why is physical AI important?
Consider a simple pathfinding algorithm like Dijkstra’s algorithm. In a purely digital graph, this algorithm finds the shortest path by optimizing purely for cost (distance, time) between nodes, assuming every path is traversable. There are no physical obstacles considered.
With Physical AI, this calculation becomes vastly more complex. A robot navigating a room must not only find the shortest route but must also account for:
- Obstacle Permanence: Is that object (a chair, a glass table) fixed, movable, or fragile?
- Physical Causality: Will traversing a certain area cause the robot to slip or knock something over?
- Dynamic Environments: Does the path intersect with a moving object (a person or pet) that requires immediate, non-collision avoidance?
The same Dijkstra’s problem must now be solved by integrating real-time sensor data and a predictive model of physics. The robot must optimize for risk and energy expenditure in a dynamic 3D space, moving far beyond a simple abstract calculation.
How to achieve Physical AI?
As we learnt the challenges in solving Dijkstra’s algorithm in real world, the first and foremost thing that is needed to achieve ‘Physical AI’ is synthetic data generation for the entities to interact with and get trained.
How is synthetic data generated?
One of the areas that I have explored is NVIDIA Cosmos. This is a platform that offers World Foundation Models (WFM). WFMs are a specialized type of foundational model in AI that is focused on simulating the real-world environments. NVIDIA is a popular provider of the WFM. Cosmos also integrates with NVIDIA Omniverse , a platform for building digital twins. The combination of Omniverse and Cosmos helps in creating controlled and highly physics-based synthetic data.
What are the advantages of Synthetic Data Generation (SDG)?
- Gathering and setting up the real-world data for the robot to learn from is time-consuming and expensive.
- Achieving data diversity in the real world and setting the real world for the repetitive setup is near impossible (e.g., simulating every possible edge case for an autonomous vehicle).
What are the the different models available in NVIDIA Cosmos?
The primary output of the WFMs are videos that are generated based on the text or the video inputs provided to the models. They are primarily classified into 2 major buckets: a) text-to-world, and b) video-to-world generation. Let us see in detail on the Cosmos models available to generate the world.
- Cosmos Predict: Generates future frames of a physics-aware world state based on simply an image or short video prompt for physical AI development.
- Cosmos Reason: Reasoning Vision Language Model (VLM) for physical AI and robotics. This model takes a video and user prompt as inputs and provides reasoning based on the prompts (e.g., “Why did the robot drop the box?”).
- Cosmos Transfer: This model generates video using text prompts and multiple spatial control inputs derived from real-world data or simulation. Omniverse and Cosmos work together and better. We can create the 3D object in spatial data with more accurate physics and ground truth information using Omniverse. The video frames from Omniverse and the user prompt will be used by the Cosmos Transfer model to generate the real-world synthetic data.

Why are NVIDIA WFMs popular?
NVIDIA’s WFMs are popular primarily due to their massive scale and their deep integration of a physics-first approach crucial for physical AI.
The key facts behind the development of the Cosmos models are:
- Unprecedented Training Data Scale: Cosmos WFMs were trained on one of the largest publicly-known datasets, consisting of 20 million hours of video data, estimated to be around 9,000 trillion tokens. This vast scale is what allows the models to learn generalized laws of physics, dynamics, and motion consistency.
- Physics-Aware Architecture: The models are explicitly designed to capture the dynamic behavior of objects, which is verified by metrics like 3D consistency and physics alignment, enabling high-fidelity simulations for robotics and autonomous vehicles.
- Ecosystem Integration: The tight coupling of Cosmos with the Omniverse simulation platform allows developers to generate perfectly labeled, physics-accurate data that accelerates the “Sim-to-Real” transition for robots.
How to start training your own model from the pre-trained model from NVIDIA?
The path to creating a custom Physical AI model is through Post-Training (or fine-tuning) the generalist pre-trained WFM.
- Select the Pre-trained WFM: Choose a base model (e.g., Cosmos Predict or Cosmos Transfer) that aligns with your end goal (world prediction or controlled generation).
- Gather Domain-Specific Data: Collect a relatively smaller dataset of real-world or high-fidelity simulated videos specific to your task, robot, or environment (e.g., a specific factory floor).
- Fine-Tuning: Use the WFM’s available Post-Training scripts (often provided on platforms like GitHub or Hugging Face) along with your new data. This process adjusts the pre-trained model’s parameters, specializing its vast general knowledge to your specific domain. This requires a strong GPU infrastructure, leveraging frameworks like NVIDIA NeMo.
- Policy Conversion: For a final robot, the fine-tuned WFM (which outputs video predictions) can often be converted or used to initialize a Policy Model (which outputs executable robot actions).
What is the purpose of NeMo Curator and Tokenizer? Where does it help?
These tools are the essential data preparation components that enable the massive scale and efficiency of WFM training.
| Tool | Purpose | How it Helps |
| NVIDIA NeMo Curator | Data Curation Framework. | Scalability and Quality: Filters, annotates, and deduplicates the petabytes of raw video data needed for pre-training. It ensures the WFM is only trained on high-quality, relevant clips with rich dynamics, accelerating video processing up to 89x compared to unoptimized pipelines. |
| NVIDIA Cosmos Tokenizer | Video Compression Tool. | Computational Efficiency: Compresses high-resolution video into a compact, fixed-size sequence of “tokens” (a latent space representation). This makes it computationally feasible to train large transformer models on video data without losing critical spatial or temporal detail. |
Who are the other providers of World models?
While NVIDIA is a prominent leader in the WFM space, particularly due to its hardware dominance and the Omniverse platform, other major research groups and tech giants are also deeply invested in world model development.
Recently, I came across the WoW (World Omniscient World model) that operates on a little bit of a different philosophy:
- Embodied Experience over Passive Observation: WoW is a model that improves itself from embodied experience rather than passive observation. Instead of just watching millions of hours of video, WoW’s philosophy argues that an AI develops authentic physical intuition by training on large-scale robot interaction trajectories—the causally rich data where an action leads to an immediate physical result. This principle closes the perception-action loop, driving a deeper, verifiable understanding of reality.
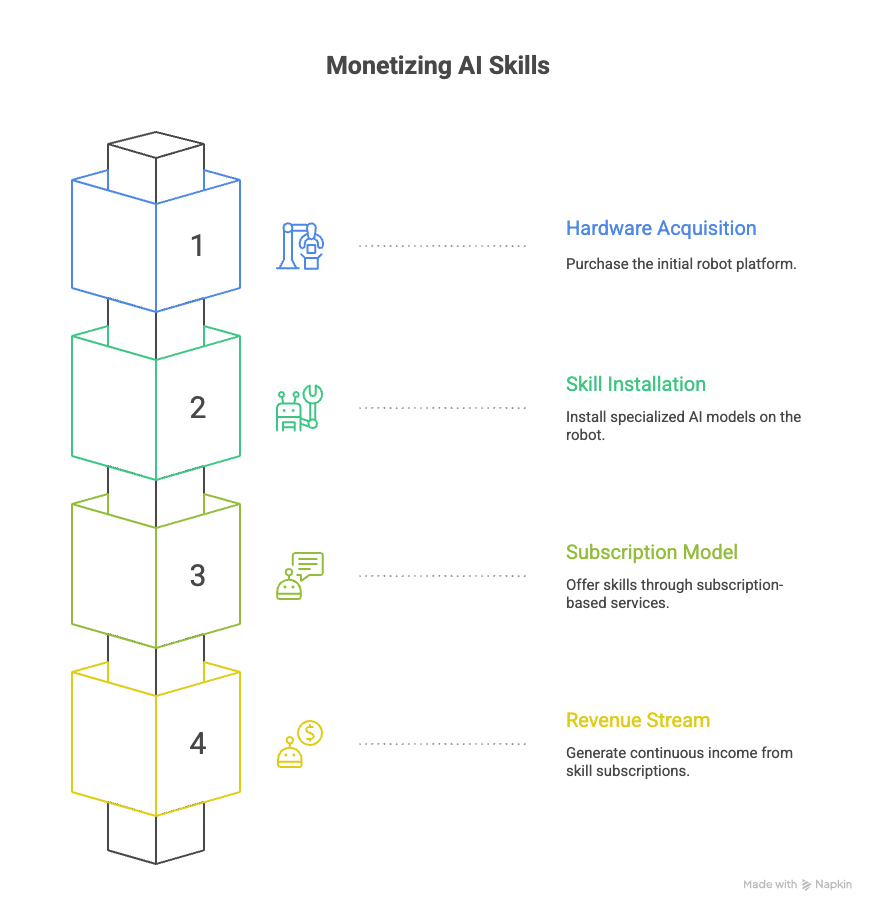
Monetization: The Physical AI Skill Subscription Model
This transformative technology creates a powerful new business model. The cost of a humanoid or autonomous robot platform (the hardware) is a one-time transaction. The real value is unlocked through specific, advanced physical skills, which can be monetized via subscription-based models.
The strategy is to have every complex capability installed as a different, specialized AI model on the robot.
| Target Market | Example Subscription Skill Model | Value Proposition & Monetization |
| Education & Sports | Tennis Coach Model, Cricket Bowling Model, Pickleball Trainer Model. | The robot acts as a personalized, tireless training partner and expert coach, analyzing and correcting form. Monetized Monthly. |
| Home/Elderly Care | Advanced Medical Assistance Model, Gourmet Cooking Model. | Provides specialized, high-liability labor and assistance (e.g., lifting patients, complex meal prep) that replaces the need for expensive human specialists. Monetized Annually. |
| Industrial/Logistics | Fine Motor Soldering Model, Hazardous Material Handling Model. | Enables the robot to perform highly specialized, dangerous, or complex tasks within regulated environments, ensuring repeatable precision. Monetized Per Task/Yearly License. |
This modular approach ensures a constant revenue stream, turning the physical robot into a platform whose value grows with every new specialized skill available in the “AI Skill Store.”
Share your experience on utilizing physical AI in your day-to-day work. Explain how you envision it to support on a large scale in the future.
Happy learning!
